Andmekogude arhiveerimine
Arhiiviväärtuslikuks hinnatud andmebaasid ehk andmekogud tuleb rahvusarhiivi üle anda regulaarsete tõmmistena. See tähendab, et arhiiviväärtusliku andmebaasi omanik peab iga 3-5 aasta järel eksportima andmebaasist rahvusarhiiviga kokku lepitud mahus andmed, salvestama need andmed avatud (arhiivi)vormingusse ning edastama rahvusarhiivi pikaajaliseks säilitamiseks.
Allpool leiad lähemat infot järgmiste teemade kohta:
- Arhiiviväärtuslikuks hinnatud andmebaasid
- Andmekogude arhiveerimise protsess
- Arhiivitõmmise vorming ja tõmmise loomise tarkvara
Loe ka rahvusarhiivi blogi artiklit andmebaaside arhiveerimise vajaduse ja kasu kohta!
Arhiiviväärtuslikuks hinnatud andmekogud
Rahvusarhiiv arhiveerib ainult arhiiviväärtuslikuks hinnatud andmekogusid. Riigi Infosüsteemi Haldussüsteemis (RIHA) registreeritud andmekogud on hinnatud rahvusarhiivi 2017. aasta hindamisotsusega nr 51.
Lisaks on andmekogudele arhiiviväärtust antud asutusepõhiste hindamisotsustega. 2022 aasta alguse seisuga on arhiiviväärtuslikuks hinnatud kokku 60 andmekogu. Aktuaalne ülevaade arhiiviväärtuslikest andmekogudest on nähtav ASTRAs: https://www.ra.ee/astra/site/databases.
Kui asutuse andmekogu ei ole veel hinnatud või soovid hindamisotsus(t)e kohta täiendavat infot, pöörduge küsimusega aadressile kogumine@ra.ee.
Andmekogude arhiveerimise protsess
Arhiiviväärtusliku andmebaasi arhiveerimine koosneb asutuse jaoks kaheksast peamisest sammust. Kogu protsessi käigus toetab rahvusarhiiv asutust nii sisuliste kui tehniliste küsimuste lahendamisel.
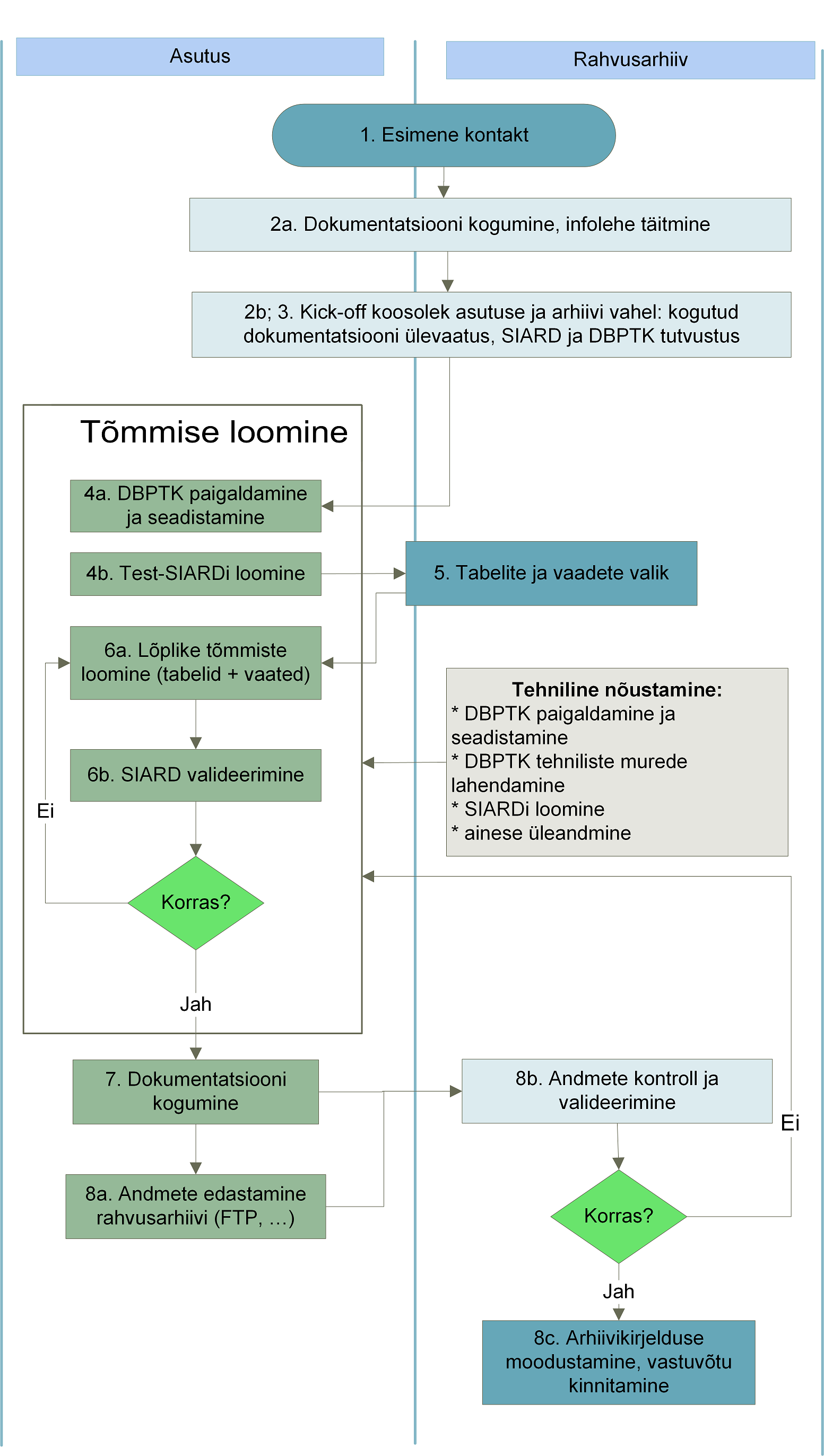
1 . Esimene kontakt
Kui olete arhiiviväärtusliku andmekogu omanik, võtab avalik arhiiv teiega ühendust andmekogust regulaarsete arhiivitõmmise tegemise osas. Samas julgustame asutusi ka ise ühendust võtma, eriti kui olete infosüsteemi oluliselt muutmas või välja vahetamas – just neis situatsioonides on vanemate andmete arhiveerimine kõige mõistlikum!
2. Tutvumine andmekogu ja selle sisuga
Enne andmekogu arhiveerimist on oluline aru saada andmekogu tehnilisest ülesehitusest, andmete mahust ja koosseisust. Kui annate andmeid üle rahvusarhiivi, palutakse teil täita lühikene infoleht, kuhu saate kirja panna andmete iseloomustuse, andmebaasi mahu, andmebaasi platvormi nime ja versiooni (Oracle, MySQL, Postgre, …), kaardistada allikad ja dokumendid milles sisaldub andmete põhjalikum kirjeldus (näiteks andmemudel, andmekataloog vms). Siinkohal on oluline mõelda ka sellele, kas andmekogust on vaja arhiveerida just struktureeritud andmeid (tabelitena), või on mõistlikum andmete eksportimine .doc või .pdf vormingus koos sobivate kirjeldustega
3. Tutvumine arhiivivormingu ja arhiveerimise tarkvaraga
Rahvusvaheliselt on relatsiooniliste andmebaaside arhiveerimiseks kasutusel vorming nimega SIARD – Software Independent Archiving of Relational Databases. See avatud vorming põhineb standardsetel XML ja SQL komponentidel ning võimaldab andmebaasi sisu salvestada kujul, mis on pikaajaliselt avatav ja taaskasutav – ka siis kui teie algne andmebaasiplatvorm ei ole arendaja poolt enam toetatud.
Andmebaasist SIARD vormingus tõmmise tegemiseks on olemas mitmeid tarkvarasid. Rahvusarhiivis rakendatud andmebaasi arhiveerimise meetodit toetab kõige paremini tarkvara nimega Database Preservation Toolkit (DBPTK), mis on võimeline ühenduma enamuse levinud andmebaasiplatvormidega, lugema neist andmeid ning salvestama need SIARD vormingus.
4. Testtõmmise loomine
DBPTK on andmebaasi administraatorile lihtne kasutada. Julgustame seda võimalikult kiiresti kasutusele võtma, tehke võimalikult kiiresti esimene testtõmmis oma andmetest! Suuremate andmebaaside puhul pakub DBPTK võimalust teha piiratud tõmmis, ehk kaasata igast tabelist tõmmisesse vaid osa andmetest. Probleemide korral on rahvusarhiiv, kui Eesti SIARD vormingu ja DBPTK tarkvara kompetentsikeskus, igati valmis aitama ja nõustama! Kui eesmärgiks on üleandmine rahvusarhiivi , ärge unustage testtõmmist meile edastamast, et saaksime omalt poolt sellele peale vaadata, kontrollida ja vajadusel juhendada teid DBPTK seadistuste osas!
5. Arhiveeritava andmekoosseisu määramine
Enamasti pole vajalik kõigi andmebaasi andmete arhiveerimine. Andmebaasis võib leiduda tehnilisi abitabeleid süsteemi kasutajanimede või protsessilogidega, või ka lihtsalt andmeid millel ei ole arhiiviväärtust.
Et leida, milliseid tabeleid on vaja ja milliseid mitte, tuleb üle vaadata andmebaasi mudel ning tühjade tabelite või väljade tuvastamiseks tutvuda testtõmmise andmetega. Üheks võimaluseks andmebaasi arhiveerimisel on ka „vaadete materialiseerimine” – see tähendab, et paljude tabelite ja seoste arhiveerimise asemel luuakse andmetest spetsiaalsed väljavõtted. Näiteks – andmebaasis eraldi tabelites paiknevad andmed inimeste, autode ja kindlustuse olemasolu kohta tuuakse arhiveerimisel kokku ühte raportisse, ehk andmebaaside terminoloogias vaatesse.
6. Põhitõmmise loomine ja valideerimine
Kui testtõmmise tegemise ja arhiveerimisele kuuluvate andmete määramise sammud on läbitud, ongi aeg päriselt arhiveeritava tõmmise tegemiseks. Enne põhitõmmise loomist soovitame andmebaasist teha eraldiseisva koopia, mida kasutadagi ainult arhiveerimise eesmärgil. Sellise koopia loomisega tagame, et arhiveerimise ajal ei sisestata, kustutata ega muudeta andmebaasis andmeid ja nii on tagatud andmebaasi andmete terviklikkus. Kui põhitõmmis on tehtud, soovitame selle ka kindlasti valideerida, ehk kontrollida kas loodud tõmmis on tehniliselt korrektne, vastavuses SIARD vormingu nõuetega ja terviklik. Valideerimise funktsionaalsuse saate käivitada DBPTK rakenduses.
7. Andmebaasi dokumentatsiooni kogumine
Pikaajaliseks säilitamiseks ei piisa ainult andmetest endist – lisaks on vaja arhiveerida ka dokumentatsiooni mis tulevastel kasutajatel aitab täpselt aru saada milliste andmetega tegemist on ning kuidas neid kõige paremini taaskasutada. Rahvusarhiiv arhiveerib seetõttu lisaks tõmmisele alati ka andmebaasi põhjalikuma kirjelduse: näiteks andmebaasi mudeli või andmekataloogi dokumendid. Samuti tuleb tähele panna, et andmebaasi arhiveerimisel ei arhiveerita kasutajaliidest, ehk seda keskkonda kus tüüpiliselt andmeid sisestatakse, hallatakse või kasutatakse. Säilitamaks tulevastele põlvedele arusaama sellisest (visuaalsest) infosüsteemi ülesehitusest, on rahvusarhiiv otsustanud lisaks andmetele ja andmete kirjeldusele arhiveerida dokumentatsiooni milles on pilte süsteemide kasutajaliidestest (näiteks koolitusmaterjalid, kasutajajuhised), palume asutusel võimaluse korral teha ka lühivideosid infosüsteemi andmete sisestamise ja kasutamise kohta.
8. Andmete edastamine rahvusarhiivi, vastuvõtu kinnitamine
Nüüd on kõik valmis selleks, et edastada tehtud tõmmis ja dokumentatsioon rahvusarhiivi. Arhiivis tehakse veelkord ära tõmmise automaatne valideerimine ning sisuline kontroll arhivaaride poolt; vaadatakse, et dokumentatsioon ja videod avanevad korrektselt ning sisaldavad õiget infot; luuakse arhiivikirjeldus et tõmmis kõigi teiste hulgast ka edaspidi leitav oleks; salvestatakse tõmmis ja dokumentatsioon turvaliselt digiarhiivi; ning allkirjastatakse vastuvõtuakt. Sellega ongi andmebaasi arhiveerimine lõppenud, ning asutus võib soovi korral üle antud andmed andmebaasist hävitada – edaspidi on võimalik neid kasutada juba arhiivist!
Arhiivitõmmise vorming ja tõmmise loomise tarkvara
SIARD vorming (Software Independent Archiving of Relational Databases) võimaldab arhiveerida andmebaasi:
- andmeid (tabelite, väljade, vaadete sisu)
- andmete struktuuri (tabelid, väljad kommentaaridega ning tabelitevahelised seosed välisvõtmete järgi)
- salvestatud protseduure ja funktsioone
- triggereid
- kasutajaid, rolle ja õigusi
- eeldefineeritud vaateid (views)
Võrreldes tavapärase SQL dumpiga on SIARD standardsem ja erinevatest andmebaasitarkvara tootjatest sõltumatu. Vormingus on lubatud kasutada ainult SQL standardis (SQL:2008) toodud andmetüüpe ja struktuure, mis tagab andmete pikaajalise taaskasutatavuse. Andmebaasi metaandmed salvestatakse standardiseeritud skeemi alusel XML vormingusse.
SIARD tõmmist on võimalik hoiustada pikaajaliselt ka off-line või near-line andmekandjal ning laadida sobivasse kasutuskeskkonda vastavalt vajadusele. Seega võimaldab SIARD vorming vähem kasutust leidvate andmebaaside arhiveerimisel olulist kokkuhoidu pideva IT taristu üleval hoidmiselt.
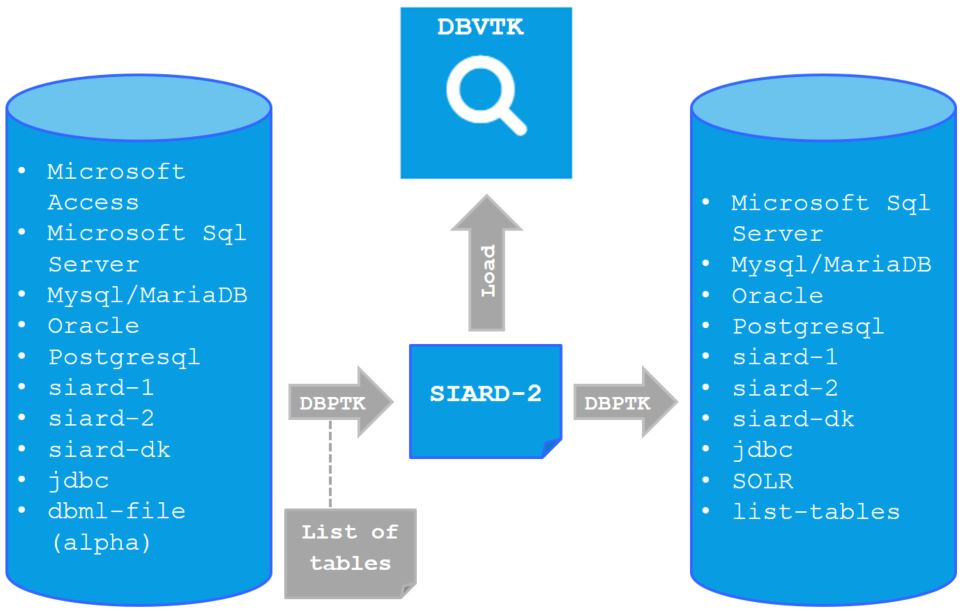
Tööriist DBPTK (Database Preservation Toolkit) on rakendus, mis on võimeline eksportima andmeid ja salvestama SIARD faili järgmistest sisenditest:
- MySQL/MariaDB
- PostgreSQL
- Oracle
- Microsoft SQL Server
- Microsoft Access
- JDBC-d toetavad süsteemid
Samuti on võimalik DBPTK abil SIARD tõmmisest andmeid otsida või laadida andmed mõnesse eelpool loetletud andmebaasisüsteemi keerukamate päringute või analüüsi jaoks.
DBPTK rakendusest on olemas kolm versiooni:
- DBPTK Developer on käsurearakendus, mida kasutavad põhiliselt süsteemi ja andmebaasiadministraatorid SIARD failide loomiseks. Lisaks on selle abil võimalik ka SIARD faile valideerida.
- DBPTK Desktop on graafilise kasutajaliidesega rakendus, mille abil saab SIARD faile luua, muuta, kasutada ja valideerida.
- DBPTK Enterprise on serveripõhine veebirakendus, mille abil saavad SIARD faile kasutada erinevad osapooled läbi veebibrauseri.
Detailsemalt võimaldavad DBPTK Desktop ja Enterprise kasutajatel:
- näha andmebaasi struktuuri, andmebaasi kirjeldust;
- näha tabelitevahelisi seoseid;
- teostada kiireid tekstiotsinguid üle kõikide andmebaasis paiknenud tabelite väljade (SOLR, noSQL);
- eksportida otsingute tulemusi CSV vormingus.
Täpsemate tehniliste küsimustega SIARDi ja DBPTK osas kirjuta aadressil lauri.ratsep@ra.ee.